- Who We Are
- Who We Help

FinTech
Healthcare
-
- What We Do
Microsoft Azure Solutions
Maintenance
Strategy
Project Rescue
MVP Development
Project Types
-
- How We Work
- Resources
- Careers

































Choosing the right FinTech software development partner is one of the most critical decisions for financial institutions, startups, and enterprises to build digital financial products. With the complexity of financial regulations, security concerns, and user demands, companies need to work with the right partners that provide financial solutions, not just software solutions.
A structured evaluation approach helps organizations identify partners with strong domain expertise, regulatory knowledge, and technical capabilities, ensuring faster time-to-market and reduced operational risks.
What Are FinTech Software Development Services
FinTech software development services involve designing, developing, testing, and maintaining digital solutions for financial operations, including payments, lending, banking, and investment management.
Financial software development services help organizations improve financial operations and user experience and comply with financial regulations. It leverages the latest technologies, such as AI, blockchain, cloud computing, and APIs, to build fast, efficient applications.
Typical FinTech solutions include:
- Digital banking platforms
- Payment gateway systems
- Lending and credit platforms
- Wealth management applications
- Insurance technology solutions
To create scalable and secure systems that process large volumes of transactions while adhering to standards, modern-day organizations require development partners.
Why Choosing the Right FinTech Partner Matters
FinTech is a highly regulated, competitive environment where technology decisions directly affect compliance, security, and trust. A good software development partner ensures your application meets regulatory requirements like PCI DSS, GDPR, KYC, and AML.
Security is another key issue, as financial applications are the most vulnerable to cyber threats. A development partner provides robust security features like encryption, authentication, and fraud detection. Scalability is essential for financial applications because, as transaction volumes increase, systems must continue to perform reliably without any downtime.
From a business standpoint, having the right development partner speeds up product launches, enhances the user experience, and fosters ongoing innovation, all of which are essential to maintain competitiveness in the rapidly changing FinTech industry.
Key Factors to Consider When Choosing a FinTech Development Partner
Industry Expertise and Domain Knowledge
- When selecting a FinTech development partner, it is also vital to consider their knowledge and understanding of financial systems, including lending, payments, and banking. This will allow the FinTech company to develop a product that complies with all relevant and stringent regulations.
- Organizations that have delivered projects across segments such as digital banking, insurance technology, and wealth management are better positioned to anticipate challenges, reduce development risks, and build solutions that are both reliable and scalable.
Compliance and Regulatory Expertise
Regulatory compliance should not be seen as secondary, as it is integral to FinTech development. The partner should be able to prove their understanding of key frameworks and regulations, including KYC/AML for anti-fraud purposes, GDPR for data privacy, and PCI-DSS for payment processing.
This is a crucial evaluation criterion because noncompliance can lead to financial penalties, operational disruptions, and long-term reputational harm.
Security and Data Protection
- Security will always be part of the equation in any financial application, owing to the nature of the data. A trusted partner will ensure the adequate implementation of security features, including end-to-end encryption, multi-factor authentication, and secure APIs.
- In addition, security audits and vulnerability assessments, along with secure coding practices, are vital for proactively addressing security risks. A good security framework is not only effective for security; it also builds customer confidence and credibility.
Technology Stack and Innovation Capability
- The effectiveness of the FinTech solution also depends on the technology used and the partner’s ability to utilize it. The top development partners have adopted the latest technologies, including artificial intelligence, blockchain, and cloud computing.
- They should also be able to recommend technology architecture that aligns with business objectives, ensuring flexibility, performance, and long-term adaptability as the product evolves.
Integration and API Capabilities
- FinTech ecosystems rely heavily on interoperability, requiring seamless integration with third-party systems such as payment gateways, banking networks, and financial data providers. A capable partner should have strong expertise in API design, development, and management.
- Effective integration enables information exchange between systems while maintaining high security and performance levels, which are critical to providing a seamless user experience.
Scalability and Performance Engineering
- Financial platforms require high transaction volumes and real-time processing capabilities without compromising speed and performance. A qualified development partner will develop systems using scalable architectures that can handle large volumes and varying workload demands.
- Using performance optimization and load management techniques, they will also provide systems with consistent application performance under peak usage conditions, which is critical for maintaining end-user satisfaction and application stability.
Portfolio and Case Studies
- An analysis of the partner’s portfolio is necessary to understand their hands-on experience. Businesses must check whether the FinTech projects they undertake are similar in nature, whether the goals were well-defined, and whether client success was documented.
- Well-established providers have case studies that demonstrate their ability to address complex business challenges, provide secure solutions, and deliver business benefits, thereby validating their credibility.
Communication and Project Management
- Effective communication and proper project management are vital to the success of FinTech projects. A good partner can use methodologies such as Agile and DevOps to ensure transparency and adaptability.
- They must have effective communication channels to convey project progress and enable iterative development, ensuring the project is moving in the right direction.

Top FinTech Software Development Companies
Several technology firms specialize in financial software development, helping financial institutions and startups build secure, scalable, and compliant digital solutions across payments, banking, lending, and wealth management ecosystems.
Telliant Systems
Telliant Systems provides FinTech software development, digital banking solutions, payment system development, API integration, and platform modernization to build secure, scalable financial systems. Focus on custom FinTech product engineering with strong domain expertise to enable faster development of compliant, scalable, and high-performance financial platforms. Enterprises and startups seeking end-to-end FinTech development with flexibility, customization, and strong domain alignment.
Accenture
Accenture delivers large-scale FinTech transformation services, including digital banking, payments, modernization, and compliance solutions. Its strength lies in combining consulting expertise with execution capabilities to build complex, enterprise-grade financial ecosystems.
IBM Consulting
IBM Consulting focuses on AI-driven FinTech solutions, hybrid cloud adoption, and blockchain integration. It helps financial institutions modernize legacy systems while improving scalability, automation, and data-driven decision-making capabilities.
Cognizant
Cognizant provides digital banking, lending, and payments solutions with strong domain expertise. It enables financial institutions to build scalable, customer-centric platforms while ensuring regulatory compliance and operational efficiency.
Capgemini
Capgemini specializes in open banking, API-led integration, and digital financial services. It helps organizations build connected ecosystems and modernize legacy systems to support seamless financial experiences.
Infosys
Infosys offers FinTech development powered by its Finacle platform, enabling core banking modernization, digital transformation, and cloud adoption for global financial institutions seeking scalable, secure solutions.
Tata Consultancy Services (TCS)
TCS provides comprehensive FinTech services supported by its BaNCS platform, helping enterprises transform banking, payments, and financial operations with scalable, secure, and globally proven solutions.
HCLTech
HCLTech delivers engineering-led FinTech solutions, focusing on digital transformation, automation, and cloud-native platforms to help financial organizations enhance innovation, scalability, and operational performance.
Wipro
Wipro offers FinTech solutions with a strong focus on compliance, risk management, and cost optimization, enabling financial institutions to modernize systems while maintaining regulatory standards and operational stability.
Finastra
Finastra provides product-based FinTech solutions for banking, lending, and payments, helping financial institutions deploy ready-to-use platforms that accelerate digital transformation and improve service delivery.
FinTech Software Development Companies Comparison (USPs & Best Fit)
| Company | USP | Best For |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Common Challenges When Selecting a FinTech Partner
- Limited understanding of financial regulation can cause serious compliance risks and potential legal issues.
- Lack of scalability can cause system performance issues as transaction volumes increase.
- Weak security measures can cause sensitive financial data breaches, threats of fraud, and unauthorized access.
- Lack of pricing transparency causes cost overruns and unclear project scope statements.
- Vendor lock-in causes inflexibility in systems and makes it hard to change vendors.
The above challenges emphasize the need for a well-structured evaluation and the right partner.
Best Practices for Choosing the Right Partner
- Prioritize domain expertise over general development skills to better align with financial goals.
- Validate compliance and security capabilities through certifications and proven implementation experience.
- Start with a pilot project or MVP to assess real-world performance.
- Ensure transparent communication with clearly defined SLAs, timelines, and deliverables.
- Choose partners offering long-term support, maintenance, and continuous product improvements.
- Assess scalability planning to handle future growth and high transaction volumes.
- Evaluate technical architecture approaches for flexibility, performance, and long-term sustainability.
These best practices help businesses reduce risks and build successful FinTech products.
Checklist for Decision-Making
- Does the partner have a track record of delivering secure and scalable FinTech solutions?
- Is the partner compliant with various financial regulations, including KYC, AML, PCI-DSS, and data privacy regulations?
- Does the partner offer advanced security features such as encryption, multi-factor authentication, and vulnerability testing?
- Is the partner capable of delivering scalable, high-performance solutions for large-scale transaction volumes?
- Does the partner offer transparent pricing models for scope, timeline, and related factors?
- Can the partner provide long-term support, maintenance, and optimization for the products?
- Can the partner offer API and integration capabilities to ensure connectivity to third-party applications?
- Are the partner’s development processes aligned with Agile, DevOps, and continuous delivery practices?
Conclusion
With the evolving nature of AI in the financial services industry, it is not just about adopting it; it is about making it scalable, secure, and high performing. This is why it is important to work with a team that has in-depth technical expertise in AI, a strong understanding of regulations, and a focus on performance and data security.
At Telliant Systems, we help businesses develop AI-driven FinTech solutions that enable more intelligent decision-making. This can be achieved in a structured manner, helping businesses avoid risks when implementing AI solutions in a competitive financial industry.

Artificial intelligence is redefining financial services by enabling AI-powered automation, data-driven financial decision systems, and highly personalized user experiences across digital platforms. Financial institutions are increasingly adopting machine learning and advanced analytics to deliver more efficient, adaptive financial solutions in a highly competitive, data-driven environment.
The scale of this transformation is significant, as the AI market in finance is projected to grow from $712.4 million in 2022 to $12.3 billion by 2032, reflecting strong adoption across the industry. This rapid growth indicates that financial institutions are moving beyond experimentation and embedding AI into core business operations.
The Evolution of AI in FinTech
The development of AI in FinTech has also followed an evolutionary path, from inflexible rule-based systems to more flexible data-driven decision-making systems. At the early stages of FinTech, traditional financial systems relied on rules and regulations to manage and process financial transactions.
As financial institutions faced increasing volumes of data, traditional methods were no longer adequate, and they began using data analytics and statistical methods for decision-making. However, these methods were also limited and more retrospective.
This addition of machine learning has resulted in a major shift away from conventional decision-making. Machine learning helps institutions learn from patterns and trends, enabling more data to be processed and more insights to be generated. The availability of cloud computing and API architectures has improved this capability.
How AI is Reshaping Financial Services
-
Transition from Static to Adaptive Decision Models
Financial systems are moving away from static, rule-based systems towards AI-based predictive models that can learn from new data points and continuously adjust the parameters of the decision-making process.
-
Continuous Data Processing and Instant Insights
Modern financial ecosystems generate enormous volumes of data, and AI helps process them in real time. AI processes millions of data points at once, enabling organizations to detect anomalies faster, make decisions more quickly, and respond to operations more effectively.
-
Tailored Financial Experiences at Scale
Customers are increasingly looking at digital experiences from FinTech institutions as the new normal. Fintech AI software solutions are helping organizations respond to this change by using customer patterns and preferences to deliver more relevant product offers.
-
Streamlining Complex Financial Workflows
The financial system comprises many complex workflows, such as financial reporting and transaction verification. These workflows are assisted and executed using artificial intelligence.
Who Uses AI in Financial Services
-
Banking Institutions
Banks use AI systems to enhance lending models, improve compliance processes, and strengthen transaction monitoring. These capabilities enable more accurate credit decisions and proactive risk management.
-
Digital Finance Platforms and Startups
FinTech startups utilize AI to create scalable, digital-first products that challenge traditional financial systems. FinTech’s ability to innovate at speed enables it to create an effortless user experience and deliver data-driven financial products.
-
Payment Ecosystem Providers
Payment platforms use AI-powered systems to process transactions safely and efficiently. Anomaly detection occurs in real time, reducing the risk of fraud, and thereby promoting trust in digital transactions.
-
Asset Management and Investment Firms
Asset management firms use AI in their models to optimize strategies and provide accurate market insights, thereby enhancing performance and delivering risk-adjusted returns.
-
Insurance Providers
Insurance providers use AI to improve the accuracy of insurance underwriting and risk prediction, automate the claims process, and improve operational efficiency and customer satisfaction.
-
Healthcare and HealthTech Organizations
Healthcare providers and HealthTech platforms are also adopting AI to manage financial processes, including billing, detecting insurance fraud, and reducing costs.
Practical Applications of AI in Financial Technology
The role of AI in FinTech is vital in augmenting decisions, security, and efficiency in financial services. By using data-driven models and analytics, financial organizations can automate their complex operations in real time.
Key Applications
- AI-driven credit risk models assess borrower credibility, predict default probability, and incorporate alternative data sources to improve lending decisions.
- AI-powered fraud detection systems use pattern recognition and anomaly detection to identify suspicious transactions in real time, reducing financial losses.
- AI-powered virtual assistants handle customer queries, support transactions, and provide round-the-clock, contextually relevant financial assistance.
- AI-powered personal finance tools analyze user behavior to provide budgeting insights, savings recommendations, and financial planning guidance.
- AI-driven trading systems analyze market data, execute trades at scale, and optimize investment portfolios based on predictive insights and risk tolerance.
Fintech AI software development is transforming financial operations by enabling faster decision-making, greater accuracy, and a more responsive, efficient system.
Limitations and Considerations
While AI in the financial services industry offers many advantages, its implementation poses several strategic challenges.
- Regulatory requirements mandate adherence to ever-changing financial regulations and standards.
- Data privacy is a concern and needs the development of effective data security models.
- Transparency and interpretability are essential for the effectiveness of AI in the financial services sector.
- The costs of implementing AI and the need for experts may hinder adoption.
Trends to Watch Out For
The future of AI in FinTech will be shaped by continuous innovation and deeper integration into financial ecosystems.
- Generative AI in FinTech enables advanced financial advisory services, automated reporting, and contextual insights.
- AI-powered autonomous financial systems are reducing reliance on manual processes by managing end-to-end operations.
- Explainable AI is gaining importance to meet regulatory requirements and improve transparency.
- The integration of AI and decentralized finance is creating new opportunities for innovation and efficiency.
Conclusion
AI in FinTech is becoming a foundational driver of modern financial systems, enabling organizations to improve efficiency, enhance decision-making, and deliver superior customer experiences. It allows financial institutions to operate with greater agility and respond effectively to evolving market demands.
Organizations that adopt AI in financial services are better positioned to strengthen governance, scale operations efficiently, and continuously optimize their processes. The future of financial software development services may be described as an adaptive, data-centric, and automated decision-making framework that has the potential to shape how financial services/products are delivered in global markets, thereby encouraging innovation, resilience, and long-term competitiveness.
I was speaking with a colleague the other day who runs technology for a retail company. He was really proud of their new customer service chatbot. It could handle returns, answer questions about store hours, and never got tired. But then he said a word that stuck with me. “My software team is still burning the midnight oil. They’re buried in old code, missing deadlines, and doing the same boring tasks over and over. The AI is talking to our customers, but it’s not helping us build anything better.”
That conversation sums up where many businesses are right now. They are starting with a chatbot because it’s an easy first step. But the real change should be how it makes your company faster and stronger.
Businesses are moving past chatbot AI because they see it only solves one small piece of the puzzle. Using generative AI in your custom software development process changes the entire game. It’s the difference between adding a helpful greeter to your store and redesigning your entire factory to build better products, faster.
This shift is happening already. Market research estimates that the global generative AI market could rise from around 16.9 billion dollars in 2024 to more than 109 billion dollars by 2030, with annual growth above 37 percent.
Now, the real growth in generative AI in software development has grown beyond flashy demos to practical tools that help people write code, design interfaces, and find bugs. It’s now about giving your builders a real advantage.
Gen AI in Custom Software Development
So, what does this actually look like in practice? It means stopping thinking of AI as just a feature you add to your software and starting to think of it as a partner that helps you build that software.
For years, building software has been very manual. Developers used to write every line, testers check every function, and designers draw every screen. Generative AI applications have introduced a new way of working: partnership. Now, a developer can explain what they need in simple words, and an AI helper can draft the code. Also, a tester can describe a problem, and the AI can come up with 50 ways to test for it. A designer can explain a user’s goal, and the AI can sketch out what the screens might look like.
This isn’t about replacing your team. It’s about making them better. Your best architects can spend less time on routine code and more on big-picture problems. Your quality assurance people would now spend less time on mind-numbing checks and more on clever ways to break the software to make it stronger.
The goal is to create a smarter, more responsive way to run your software product development. The AI becomes a built-in team member, helping from the first brainstorm to the final instruction manual.
Use Cases in Development
Let’s talk about where this partnership shows up in the actual work of creating software. Here are the places it’s making a real difference today.
-
AI Code Generation is the big one everyone’s discussing
Tools like GitHub Copilot work like a partner sitting next to your developer. As they type, the tool suggests what might come next. But it’s smarter than just guessing words.
A developer can write a note like “// check if this email address is valid,” and the AI will often write the whole chunk of code to do that job. It speeds up the first draft immensely. A study by GitHub found that developers using their AI tool finished tasks 55% faster. That’s not just about speed; it’s about freeing up your developers’ brainpower for the hard stuff.
-
Generative AI for User Experience (UX) and Design
Before anyone writes a single line of code, AI can help figure out what the software should look like. Designers can ask an AI to create sample screens from a description, try out different color schemes, or map out how a user might click through an app. This lets teams try out ideas quickly in minutes instead of days and ask, “what if?” without a huge cost.
-
AI in Software Testing and Quality Assurance
This is a huge area for impact. Generative AI can automatically write test scenarios from simple descriptions. It can create fake, but realistic, test data so you don’t have to use real customer information and risk a privacy problem.
It can even point out parts of your software that haven’t been tested enough. You end up with software that’s more reliable because it’s been checked more thoroughly.
-
Intelligent Documentation and Knowledge Management
Keeping documentation updated is a chore everyone hates. AI can now help with that thankless task. It can look at code changes and automatically update the relevant instructions.
It can summarize long email threads about a technical problem or write the “what’s new” notes for the latest update. This turns documentation from a boring afterthought into something that almost takes care of itself.
Technical Implementation
How do you make this work in real life? It’s not as simple as downloading an app. Getting AI software integration right needs a smart approach.
- First, you have a choice: use a general, out-of-the-box AI or create your own. For most enterprise AI needs, the best path is in the middle. You start with a powerful brain (like GPT-4 or Claude) and then teach it your company’s way of doing things. How? You feed it your own code, your internal docs, your style guides. This teaches the AI how your company talks and works. The help it gives will fit your patterns better and be safer to use.
- Second, you need to connect the AI to your own brain. This is where a method called Retrieval-Augmented Generation (RAG) is key. A basic AI answers from its general knowledge. A RAG system is different. It first goes and looks up information in your own company files, docs, or code. Then it forms an answer based on what it found there. This makes the answers more accurate and less likely to be made-up, because they’re grounded in your actual work.
- Finally, this all needs to fit into the tools your team already uses every day. Artificial Intelligence (AI) needs to live inside their coding software, their project trackers, and their version control systems. If it feels like a separate, clunky tool they have to log into, they won’t use it. It has to be right there where the work happens.
Challenges & Requirements
This journey has some bumps in the road. Knowing about them helps you steer clear.
- Data Privacy and security are the biggest worries. You absolutely cannot send your secret source code or business logic to some public AI on the internet. Your AI system needs to learn and run in a secure, private space you control. This is why teaching the AI on your own secure servers or using very tightly controlled cloud services is an absolute must.
- Output Quality and “Getting It Wrong” is a real issue. AI can sometimes write code that looks right but has a hidden bug or suggest something that doesn’t make sense. This makes the human more important than ever. You are building a system of human plus AI, not AI alone. The developer is still the boss. They must look over and approve every important suggestion. Having a good, strong process for code review is your best safety net.
- Working with Old Systems is a fact of life. Your most important software is often the oldest. Getting new AI tools to work smoothly with these old, giant systems can be tricky. The answer is often to build a simple modern bridge, which is a new layer that lets the AI talk to the old system without having to rebuild the whole thing from scratch.
- Skill Gaps and Team Worry might be the toughest part. This is a new way to work. Developers need to learn how to effectively ask the AI for help. Some people might be skeptical or afraid that the technology will take their jobs. You have to be clear: this is a tool to make their jobs better and not to replace them. You need good training, and you need to show them how it helps.
A 2025 Gartner report noted that 75% of companies say the hardest part is getting people to change their daily habits.
ROI & Adoption Framework
How do you make sure this is worth the investment? You need a clear plan that ties directly to getting real work done. Don’t start with the shiny technology. Start with a specific headache.
-
Start Small with a Pilot
Don’t try to change everything at once. Pick one single, annoying problem. For example, try an AI coding helper with one small team on one clear project. Or use AI to write tests for just one part of your software. Measure everything: how long did it take? Were there fewer mistakes? Did the team like it? A small pilot shows you what works without big risk.
-
Measure What Actually Matters. Look beyond technical numbers.
- Speed: Are we getting new features to customers faster?
- Quality: Is the software breaking less often?
- Capacity: Can our team do more valuable work with the same people?
- Happiness: Are our engineers less frustrated with boring tasks?
-
Grow with Rules
Once your pilot works, write down how you did it. Create a simple rulebook for security, for how to review AI-suggested code, and for how to ask the AI good questions. Have a small group of people who help other teams learn and keep everyone on the same page.
-
Focus on Helping People
Frame everything around making your team’s life better. The real payoff isn’t just saving money. It’s being able to try new ideas faster, fix problems quicker, and build software you’re truly proud of. Experts at McKinsey & Company estimate that generative AI could add between $2.6 trillion and $4.4 trillion to the global economy every year. A big piece of that will come from building software and products in this new, faster way.
Conclusion
We started with a story about a chatbot, a single, helpful machine. We ended by talking about changing how your whole team builds things. That’s the shift you need to see.
Generative AI is moving from the front desk to the workshop. The biggest advantage won’t go to the company with the best chatbot. It will go to the company that can build, adapt, and solve problems with the most speed and skill. It’s about using generative AI in custom software development to create better products.
This isn’t science fiction. The tools are here. The early success stories are written. The question for you is no longer if this will change how software is built, but when you will decide to build this way. Your team’s energy, your product’s quality, and your competitive edge depend on that choice.
If you’re looking at your own development process and wondering how to start weaving in these AI capabilities without slowing down, that’s a conversation worth having. At Telliant Systems, we collaborate with teams every day to bring these powerful ideas to life, building smarter software development pipelines that are ready for what’s next.
Enterprises are accelerating cloud adoption to improve scalability, reduce infrastructure management costs, and support digital services. However, it is not only a technology shift but also a strategic change that affects efficiency, development speed, and innovation. Many organizations believe that migrating to the cloud will automatically modernize their environment, but migration and modernization are two distinct processes.
Cloud migration involves moving applications and infrastructure to the cloud, while cloud app modernization focuses on rearchitecting applications to maximize cloud-native capabilities. Unplanned migration may lead to continued inefficiencies, whereas unplanned modernization may result in increased costs. It is essential for businesses to carefully consider both options to ensure that their cloud investment meets their performance, efficiency, and growth requirements.
What Is Cloud Migration
Cloud migration is the process of moving applications, databases, and workloads from on-premises infrastructure or legacy hosting environments into public, private, or hybrid cloud platforms. The goal is to relocate systems safely while maintaining business continuity.
In most cases, applications operate in the cloud the same way they did previously, with minimal architectural changes. This allows organizations to shut down physical data centers, reduce hardware maintenance costs, and improve availability using cloud infrastructure. Migration also enables faster provisioning of computing resources, allowing IT teams to scale up or down based on demand rather than maintaining excess capacity.
Migration provides immediate infrastructure benefits with limited engineering effort. However, migrated systems may continue to operate inefficiently because their architecture was not designed for cloud environments.
What Is Cloud Modernization
Cloud modernization focuses on transforming applications to fully benefit from cloud-native technologies. Instead of simply moving systems, modernization improves how applications are built, deployed, and scaled.
Modernization may include breaking up monolithic applications into modular services, setting up automated deployment pipelines, and leveraging managed cloud services. Such transformations enable applications to scale automatically, making them more reliable and requiring less operational effort.
From a business perspective, modernization enables faster feature delivery, easier integration with analytics and automation tools, and improved resilience. Although cloud app modernization requires more engineering effort than migration, it delivers stronger long-term efficiency and innovation capability.
Key Differences Between Cloud Migration and Cloud Modernization
Cloud migration and modernization differ in scope, complexity, and business impact. Migration focuses on relocation, while modernization focuses on architectural transformation.
| Factor | Cloud Migration | Cloud Modernization |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Migration improves where applications run, while app modernization improves how they operate.
Cloud Migration Strategies and Their Connection to Modernization
Enterprises use structured migration strategies to determine how workloads transition to the cloud, with some approaches focusing on relocation and others involving modernization.
Rehosting moves applications without modifying their architecture, enabling rapid migration. Replatforming introduces limited optimization, such as using managed databases while keeping core application logic unchanged. Refactoring or rearchitecting redesigns applications using microservices and automated scaling, representing full modernization.
Repurchasing involves replacing legacy software with SaaS applications, thereby eliminating the need for infrastructure management; retiring involves removing outdated applications; and retaining involves keeping applications when migration is not immediately feasible. These approaches show that migration and modernization exist along a continuum.
When Cloud Migration Is the Right First Step
Cloud migration is often the most practical option for enterprises with large, legacy environments that must be migrated quickly. Organizations can reduce hardware maintenance costs, improve infrastructure reliability, and exit physical data centers without disrupting operations.
Since migrating these systems enhances disaster recovery, enables automated backups, and provides scalable infrastructure without requiring significant application changes, it is the best option when applications are stable, but infrastructure costs are increasing.
Migration allows IT teams to gain cloud experience before undertaking complex modernization initiatives, but it does not resolve architectural limitations that can affect long-term efficiency.
When Cloud App Modernization Becomes Necessary
Cloud app modernization is necessary when legacy applications limit scalability, speed, or innovation, as manual scaling and slow deployment processes make them less efficient in operations.
Modernization enables applications to scale independently, support automated deployment, and integrate with analytics and automation platforms. This improves responsiveness, reduces downtime, and accelerates development cycles.
Customer-facing applications benefit most from cloud modernization because their performance and availability directly affect customer experience and revenue while enabling faster innovation and more efficient service delivery.
Cost, Risk, and Long-Term Value Considerations
The investment required for the two is different. Migration requires less investment but can result in higher operational costs if not used effectively. Modernization investments are higher, but by using managed services and scaling, they can achieve efficiency improvements and lower maintenance costs.
Migration has lower initial technical complexity, whereas modernization has greater complexity but lower long-term operational risk by removing dependencies on legacy systems, forcing enterprises to make trade-offs between short-term and long-term investments.
Migration-First, Modernization-First, and Hybrid Approaches
Most enterprises adopt phased strategies instead of relying on a single approach, using a migration-first model to move workloads quickly while modernizing gradually. A modernization-first strategy is adopted for applications that cannot operate effectively in a cloud environment without architectural redesign.
The hybrid approach is the most common strategy because it allows organizations to migrate stable systems while modernizing business-critical applications, enabling them to manage risk while steadily improving performance and scalability.
Choosing the Right Strategy for Enterprise Workloads
Selecting the appropriate strategy requires evaluating the application architecture, business value, and future requirements to decide whether migration can provide quick infrastructure value or whether modernization is necessary for future scalability and performance.
Applications involved in customer experiences, analytics, or innovation are good candidates for modernization because modernization enhances scalability and flexibility. The enterprise should also consider internal expertise, costs, and timelines when planning its cloud strategy. A systematic workload analysis helps ensure alignment of cloud investments with business needs and drives value.
Enterprise Example: Migration vs Modernization Impact
Consider an enterprise operating a legacy customer management platform in its own data center, where migration improves infrastructure reliability and removes hardware maintenance costs but does not resolve deployment and scaling limitations.
With a modernized system that has a modular design and automated deployment, the organization can deploy changes quickly, scale effectively, and leverage analytics. This improves operational efficiency and customer experience while reducing maintenance complexity.
This example demonstrates that migration improves infrastructure flexibility, while modernization improves application capability.
Conclusion: Migration Builds the Foundation, Modernization Delivers the Advantage
Cloud migration and cloud modernization are two processes with distinct yet complementary roles in businesses’ adoption of cloud technology. Cloud migration helps businesses move their applications to a scalable cloud infrastructure. On the other hand, cloud modernization is the process of revamping applications to fully utilize the cloud.
Enterprises that combine migration with cloud app modernization can improve efficiency, reduce technical debt, and build systems that support continuous innovation. A phased approach allows organizations to control costs, reduce risk, and maximize the long-term value of their cloud investments.
Why Healthcare Application Security Requires More Than HIPAA Compliance
As healthcare systems become more digital and interconnected, application security has become a business-critical risk rather than a technical afterthought. Ransomware attacks, credential abuse, and data theft incidents are on the rise in the healthcare sector. These applications are attractive targets because they handle valuable electronic Protected Health Information (PHI), depend on complex integrations, and allow remote access for many users and systems.
Although HIPAA outlines required security measures, simply following these rules often does not prevent actual breaches. Healthcare executives, product teams, and engineering stakeholders can use this playbook to translate HIPAA regulations into applicable, risk-focused cybersecurity procedures for contemporary healthcare applications.
Understanding HIPAA Through a Cybersecurity Lens
1. What HIPAA Covers:
HIPAA applies to all healthcare application components that create, store, process, or transmit electronic Protected Health Information. Protecting ePHI means ensuring confidentiality, integrity, and availability as operational security outcomes.
2. What This Means for Software Teams:
Application engineering and design are directly impacted by HIPAA protections. Code, infrastructure, and system configuration must be used to implement and enforce authentication, authorization, encryption, logging, and monitoring.
3. What HIPAA Does Not Guarantee:
Merely having policies, audits, and compliance assessments in place is not enough to prevent breaches. If technical controls are not enforced continuously, there is always a security risk.
How HIPAA Safeguards Appear in Real Healthcare Applications
HIPAA safeguards span across three layers of a healthcare application, each addressing a different risk dimension.
Administrative layer
- Governance and accountability define who is responsible for security decisions and how they are enforced.
- The management of the workforce and vendors through employee training, access controls, and vendor governance reduces human and third-party risk.
Physical layer
- Devices and access environments control how laptops, mobile devices, and workstations interact with healthcare systems.
- Remote and distributed access points manage security risks introduced by remote users and decentralized teams.
Technical layer
- Application controls and enforcement use role-based rules, authorization, and authentication to limit access to ePHI.
- In addition to supporting detection, investigation, and response, monitoring and traceability offer insight into system activity.
Applying Administrative Safeguards in Practice
Application controls and enforcement use role-based rules, authorization, and authentication to limit access to ePHI. In addition to supporting detection, investigation, and response, monitoring and traceability offer insight into system activities.
Ongoing risk assessments help identify exposure across application architecture, integrations, and user access patterns. Strong access governance depends on well-defined roles, structured approval processes, and regular access reviews.
These must be managed with contracts and technical controls. Leadership involvement keeps security priorities in line with business goals and technology strategy.
Applying Physical Safeguards in Practice
Physical safeguards focus on controlling where and how people access healthcare applications. Clinician laptops, tablets, and mobile devices are common points of exposure because they are often used in different locations and networks.
Shared workstations and clinical environments introduce additional risk when multiple users access systems from the same devices. In order to prevent unauthorized physical or remote access to systems that manage sensitive patient data, cloud-hosted infrastructure significantly increases the attack surface, requiring explicit accountability and uniform controls.
Protection depends on:
- Device authentication and encryption
- Controlled physical and remote access
- Monitoring of distributed usage patterns
As healthcare becomes more distributed, physical safeguards must adapt to flexible work models without increasing risk.
Applying Technical Safeguards in Practice
Technical safeguards are implemented directly within healthcare applications to enforce consistent protection of electronic Protected Health Information. Access control determines who can access ePHI, what actions they are permitted to perform, and under what conditions access is allowed.
Strong integration security ensures that APIs authenticate and authorize every request and validate and monitor all data exchanges. These controls work together to reduce unauthorized access, limit misuse, and make sure interactions between internal systems and external services are secure.
Maintaining Visibility in Healthcare Applications through:
- Comprehensive audit logging
- Continuous activity monitoring
- Rapid detection of misuse or anomalies
Building Secure Healthcare Apps: From Architecture to Deployment
Secure-by-Design Principles for Healthcare Software
- Design application architectures with security and data protection as core requirements.
- Try to limit exposure of electronic Protected Health Information (ePHI) by using segmentation and carefully managing data flows.
- Address security risks early to reduce downstream remediation costs.

Embedding HIPAA Safeguards into the SDLC
- Make sure to integrate security requirements into planning, design, and development phases
- Apply HIPAA safeguards consistently across development and release workflows
- Validate security controls before deployment and during updates
DevSecOps Practices for Healthcare Applications
- Automate security checks as part of the continuous integration and delivery (CI/CD) process.
- Maintain secure configurations and properly manage dependencies.
- Ensure fixes can be made quickly without slowing delivery.
Continuous Security Testing and Validation
- Regularly perform vulnerability and security tests.
- Validate security controls after changes, integrations, or scaling up.
- Keep an eye on how adequate your safeguards are over time.
How Telliant Systems Helps Secure Healthcare Applications
Telliant Systems helps healthcare organizations secure applications by combining regulatory expertise with secure software engineering practices. Our teams create and deliver HIPAA-compliant healthcare applications. We include security in every part of the process, from design to development, testing, and deployment. We support compliance-focused development while also working to lower real-world security risks in our systems and integrations.
Our focus areas
- Regulatory-aligned development
- Application security by design
- Data privacy protection
- Secure interoperability and APIs
- Risk and compliance automation
Telliant’s cybersecurity services help healthcare organizations protect patient data by aligning regulatory requirements with practical, real-world security practices. This way, you can stay compliant and grow your applications without worrying.
A Practical Path to HIPAA-Aligned Cybersecurity
You need to know more than just the rules to secure healthcare applications. Infrastructure, application design, and governance must all be consistent. When you have the right strategy and the right partner to help you, aligning with HIPAA can actually lead to greater resilience and growth, rather than just being a box to check.
Although HIPAA security measures provide a good starting point, complete protection is achieved by integrating them into regular engineering and operational procedures.
For any business, cloud-native isn’t just a trend; it’s a necessity. Many entrepreneurs operate their business under severe pressure to innovate faster, scale seamlessly, and diminish the overall expenditure without ever risking reliability. Cloud-native application development stands as the backbone of digital transformation, but not all partners deliver the same results.
That’s the point where the Telliant Systems is distinct. With connected engineering expertise, an enterprise-first mindset, and measurable delivery practices, Telliant has become the preferred partner for organizations that are seeking technical excellence and core alignment.
The Cloud-Native Imperative for Modern Enterprises
Cloud-native development is about making applications in the cloud. It’s more about designing systems that are scalable and adaptive. Making the most of microservices, containers, continuous integration, and automated deployment pipelines.
Enterprises are no longer a measure of success by asking if an app “works.” They measure how rapidly it shifts, how efficiently it scales down, and how cost-effectively it runs. And in this race for integrity, implementation maturity separates leaders from laggards.
1. Proven Enterprise-Grade Cloud Expertise
When discussing cloud-native transformation, experience is important. Many industries can deploy microservices; virtually no other business can architect the entire ecosystem that supports global workloads. Telliant’s strength lies in translating complex enterprise goals into resilient, cloud-native architectures.
From multi-cloud to orchestrated containers up to automated scalability, Telliant’s teams have the tools to mould real-world problems into global solutions. Telliant’s engineers are fluent in public services like AWS, Azure, or GCP, but more importantly, Telliant’s engineers know how to architect for the purpose of performance, compliance, and price.
Where others live in the defined space during the “build” phase, Telliant owns the entire lifecycle from design to continuous delivery to lifecycle support to ensure every cloud-native solution meets the enterprise business KPIs and compliance requirements.
2. End-to-End Ownership, From Strategy to Scale
Businesses want a partner who will own results and outcomes, not just a vendor who disappears after a project is deployed. Telliant is unique in its end-to-end encrypted model as we go beyond merely offering a deliverable as we walk along with our client from cloud strategy to architecture to development, deployment, and continual optimization. This highly incorporated approach reduces the friction between development and operations teams, helping the enterprise obtain faster time-to-market and reduced operational overhead.
Rather than taking a transactional stance, Telliant incorporates itself as a long-term strategic ally, identifying blockage and performance issues before they impact customers.
Although some firms rely on speed, Telliant prioritizes sustainable scalability, making sure that every release is not fast but future-ready. This complete spectrum engagement makes Telliant a trusted choice for businesses looking to amplify at scale without ever losing control over quality or cost.
3. Engineering Quality That Reduces Long-Term Costs
In the software development industry, making sacrifices up front generally means incurring additional expenses down the road. Telliant’s engineering philosophy states that quality is an important measure of ROI, advocates a focus on maintainable code, automated testing, and solid CI/CD pipelines that decrease expensive rework and downtime.
Enterprises trust Telliant’s engineering teams because they deliver components with production-grade reliability on day one. When combined with strategic QA automation, Telliant’s test-driven development practices ensure that minimal issues arise in the production environment after deployment.
This diligent engineering process leads to measurable savings. Applications require fewer patches, are able to scale more effectively, and integrate easily with other systems present in the enterprise. Clients experience attributable reductions in maintenance costs over time, a calculation many fail or forget to consider when evaluating other vendors.
On the other hand, low-cost providers have a consistent history of delivering solutions that are fast and fragile. Telliant’s commitment to diligence guarantees that enterprise teams spend less time on fixing issues and more time on driving innovation
4. Deep Domain Knowledge Across Regulated Industries
Cloud-native success isn’t just about technology; it’s about having the right knowledge. Each and every industry has its own regulatory, security, and compliance landscape, from HIPAA in healthcare to SOC 2 in financial services. Telliant’s experience all across the regulated domain gives a strong benefit. The panel of experts at Telliant Systems doesn’t merely build but offers practical outcomes that anticipate industry-specific criteria. For instance, in the healthcare sector, protecting data interoperability and an audit-ready framework is essential. Whereas in fintech, it has a robust transaction system with real-time monitoring.
This level of contextual understanding allows Telliant to align technical solutions with both compliance mandates and business objectives. Enterprises trust them not just to deliver applications but to ensure those applications thrive under the scrutiny of regulators, auditors, and enterprise security teams alike.
Other vendors may bring technical skill, but Telliant brings industry fluency, a rare combination that drives confidence and accelerates adoption in mission-critical environments.
5. Transparent Collaboration with Measurable Outcomes
An authentic digital transformation relies on trust and transparency. Telliant’s cooperative model gets you the best of both worlds. Clients get 100% visibility into the progress, metrics, and decision-making since day one. Every project is linked to measurable metrics that result in open and measurable outcomes. Outcomes might be more frequent release cycles, much greater uptime, or reduced framework costs.
This transparency extends to communication as well. Telliant’s teams work as an extension of the client’s organisation, using agile sprints, real-time dashboards, and continuous feedback loops to maintain clarity at every stage. Telliant believes in co-shared accountability, in contrast to vendors that remain behind closed doors. They don’t just promise results, they prove them, with performance benchmarks and metrics for ROI that drive measurable results.
The result is a relationship not based on assumptions but instead based on data. Enterprises remain informed, empowered, and confident that their investment is translating into measurable value.
Choosing the Right Partner for Cloud-Native Success
Cloud-native adoption is more than technical migration; it’s a strong business movement. The right development partner shows how well that evolution assists your long-term vision. With time, Telliant Systems has proved why enterprises all across industries choose it: unmatched technical depth, holistic engagement, disciplined engineering, domain fluency, and transparent collaboration.
These qualities turn cloud-native development from a cost centre into a strategic growth engine.
For organizations ready to modernize with measurable outcomes, Telliant delivers more than solutions; it delivers sustained business impact. Request a consultation today and discover how Telliant Systems can accelerate your cloud-native journey with confidence and clarity.
Functional testing is one of the primary quality assurance disciplines, ensuring that software operates as expected according to both business goals and technical requirements. Instead of looking at the internal code, functional testing checks whether important features, workflows, and integrations function correctly in real-world situations.
In modern software environments, even minor functional issues can disrupt business processes, delay releases, and increase operational risk. Good functional testing helps solve these problems by consistently verifying application behavior early. This approach allows organizations to deliver software that is stable, predictable, and reliable.
This article looks at functional testing services from the perspective of delivery and execution. It explains how functional testing is set up and carried out, highlights best practices that improve release stability and quality, and discusses how organizations can track their return on investment through lower defect costs, quicker release cycles, and a better user experience.
What Is Functional Testing?
Functional testing is a software testing technique that verifies the actions and outputs of software features against the requirements outlined in functional specifications, user stories, use cases, or business process models. It is usually done without considering the internal code structure. This black-box approach concentrates only on inputs, user actions, and expected outputs.
This method works for individual features, such as authentication flows, as well as for complete workflows that involve multiple modules or services. Functional testing validates software behavior from a business perspective, ensuring the application consistently delivers the intended value.
Functional Testing vs Non-Functional Testing
Setting reasonable expectations for the scope and results of testing requires an understanding of the distinction between functional and non-functional testing. Both are necessary for software quality, but they deal with different risks.
| Aspect | Functional Testing | Non-Functional Testing |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
From a business standpoint, functional testing forms the foundation of quality assurance. A system that performs well under load but delivers incorrect results still fails to meet its core purpose.
Functional Testing Process
A clear, repeatable process ensures that functional testing is measurable, traceable, and aligned with delivery goals. Most functional testing services follow a structured lifecycle.
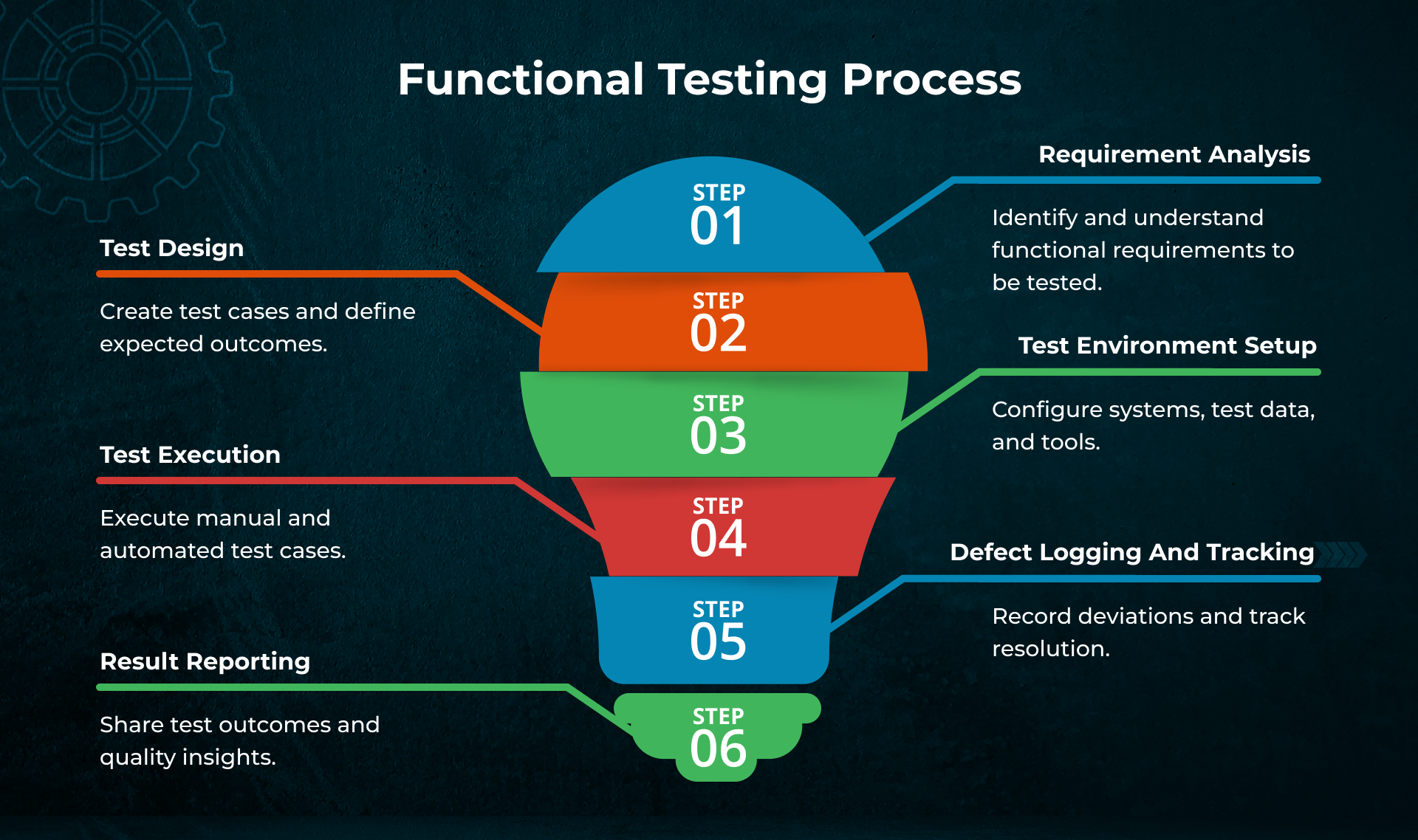
This process ensures that functional coverage remains aligned with documented requirements and business expectations throughout the software development lifecycle.
Types of Functional Tests Covered
Functional testing services normally consist of multiple testing levels that are combined to guarantee complete coverage
- Unit Testing: Validates individual functions or components in isolation.
- Integration Testing: Verifies interactions between integrated modules or services.
- System Testing: Evaluates the complete application in an end-to-end environment.
- Regression Testing: Tracks the existing functionality that has not been affected by recent code changes.
- User Acceptance Testing: Confirms that the system meets business expectations using real-world scenarios.
Each type addresses a different risk level and collectively strengthens software reliability.
Best Practices for Functional Testing
- Features that influence customer satisfaction, company revenue, and compliance should be tested before others.
- Each test case must be associated with the requirements to ensure complete coverage and the ability to assess the effect.
- For repeatable scenarios, use automation; for exploration and usability, use manual testing.
- To minimize rework, provide quicker feedback, and stabilize releases, run tests early in the development process.
- Maintaining proper test documentation will not only facilitate audits and communication but will also be a continual source of quality improvement.
Measuring ROI of Functional Testing Services
ROI from functional testing services is driven by both direct financial savings and indirect operational improvements.
Key ROI Drivers
- Reduced defect-resolution costs: Fixing defects found during development is much cheaper than fixing those found in production.
- Faster release cycles: Good functional testing reduces release delays and the need for post-release fixes.
- Improved customer experience: The number of functional defects that reach production is reduced, leading to higher user satisfaction and lower support costs.
- Actionable quality metrics: Metrics like defect leakage, test coverage, and cycle time help measure quality improvements.
Functional Testing Service Delivery Models
Functional testing services can be delivered through:
- In-house QA teams are embedded within development teams.
- Dedicated testing partners with scalable knowledge
- Hybrid approaches that combine external execution with internal ownership
Final Perspective
Functional testing is a crucial component of quality control, ensuring that software applications function as intended. It checks that important features meet documented requirements and deliver reliable results for users, confirming that the system behaves as the business and end users expect before release.
This methodical approach produces quantifiable business outcomes. Organizations gain improved release stability, faster time-to-market, lower defect repair costs, and increased customer satisfaction. Functional testing services provide long-term investment in software quality. This investment directly supports operational strength and continuous business expansion.
Software is not just a part of the support function; it is the engine that drives growth, customer experience, and sustainable competitiveness. Custom software isn’t optional anymore, whether it’s improving operational efficiency, digitizing new products, or scaling customer platforms. Yet, one question keeps echoing in every boardroom: what is the actual return on investment? The market for custom software development services in the USA was appraised at USD 10.7 billion in 2024 and is predicted to hit USD 29.7 billion by 2030 with a yearly increasing rate of 18.5%.
A number of businesses still have a difficult time calculating or even determining what their actual ROI is on software development. Some projects never get launched completely, and some projects find out too late that inefficiencies and technical debt have slowly drained their budget. The reality is, when it comes to custom software development, it’s not about spending less; it’s about being sure that every dollar spent will produce a quantifiable return to your business.
That’s where understanding ROI becomes a competitive differentiator, and where Telliant Systems consistently stands apart.
Why ROI Matters More Than Ever
The digital economy of today is based on speed, scalability, and efficiency among other things. It is a must for the companies to come up with new products faster, provide better performance, and, at the same time, be more flexible in their operations, with the additional burden of having less budget and lower margins than before. Hence, the ROI has been repositioned from being a back-office measurement to a business strategy communicating with the front line.
A strong ROI in custom software typically translates into:
-
Accelerated Time-to-Market
Faster deployments allow companies to seize opportunities sooner. Each week saved in the release process will translate into tangible market share.
-
Reduced Operational Costs
Reducing manual errors relating to automated workflows will cause your long-term maintenance costs to be lower.
Improved Scalability and Customer Experience
Software designed to scale ensures that when your user base doubles, your costs don’t.
However, the other side of the ROI is equally important. The reason why most organizations still fall into the trap of chasing lower upfront costs than long-term value is. Low-cost vendors might seem attractive at first, but the costs that are unidentified and remove ROI over time.
Inexpensive code can be expensive to modify. If the software does not support the business strategy, all return on investment will fail. Today, companies are no longer asking the question, “How much will this cost?” but rather are asking, “How much value is it going to create, and how fast?”.
Measuring ROI in Practice
Having a sound understanding of ROI isn’t just about measuring profits and software deployment; it’s about keeping track of performance at every moment of the developmental cycle. As for most of the businesses, that means signalling three major pillars.
-
Operational Efficiency Gains
Custom-made systems always enhance productivity, but automating repetitive tasks, incorporating data flows, and reducing any sort of redundant tools. For instance, replacing a legacy system that needs three manual inputs with a single automated process that delivers measurable man-hour savings.
-
Revenue Growth Through Enablement
A full-on custom platform can open an entirely new sales funnel. For example, an insurance firm may launch a digital claims portal or even launch a mobile app that improves overall engagement and retention, which translates into measurable ROI.
Cost Avoidance and Risk Reduction
Code that is well structured and of high quality minimizes the chances of expensive downtime, data loss, or later systems re-engineering. One of the most ignored, but most powerful, forms of ROI is to prevent problems before they occur.
Telliant vs. Competitors: The ROI Difference
Many firms proudly claim to have “custom software”. But only a handful of them ever process their engineering, culture, and delivery models around measurable business ROI. That’s the foundation of Telliant Systems, where success isn’t judged by a written code, but by the outcome. Here’s what makes Telliant distinct from the usual development vendors in the market.
Depth of Engagement vs. Project-Based Vendors
What a typical firms operate on a project-to-project model, Telliant embeds itself into the client’s business ecosystem. We not only deliver a product, but we also co-own the results. That means aligning software features with specific KPIs, success metrics, and operational realities. As a result, it’s a partnership that measures ROI at every phase, not just at a finish line.
Engineering Quality vs. Quantity of Output
What’s even more amazing is how Telliant takes a unique approach; we invest deeply in architecture, testing, and constructive feedback cycles to make sure that each and every line of code contributes to long-term stability and scalability. Our entire dedicated testing and QA team monitors performance, usability, and security, making sure that the ROI compounds over time the decline through rework or maintenance costs.
Expertise and Industry Knowledge
Telliant’s engineering teams leverage cross-industry experience across healthcare, finance, SaaS, and enterprise technologies. This depth of the domain enhances discovery, mitigates risk, and bridges technical decisions with outcomes for the business. Unlike generic developers, Telliant engineers understand the business rationale and connection of each technical milestone.
Transparent Collaboration and Measurable Impact
Transparency is fundamental in ROI-focused development. Telliant builds transparency into the process through real-time, reportable outcomes; collaborative, agile feedback; and dashboard measurement of progress and performance at significant milestones in the process are all visible to clients. In this way, there is mutual accountability and confidence; you can see exactly how each sprint contributes to your overall business objectives.
ROI with Telliant vs. Typical Vendor
| Criteria | Typical Vendor | Telliant Systems |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Turning Software from Expense to Investment
Custom software development isn’t some discretionary spend. It’s a core investment that defines whether your business is staying ahead or falling into a pitfall. But what needs to be known is that not every dollar you spend delivers an equal value.
When made with the right software product development partner, software becomes the most measurable support system, improving overall efficiency, unlocking new revenue, and even compounding returns long after launch. Telliant Systems has consistently shown that the return on investment is a discipline, not just a buzzword. Telliant turns technology spend into sustained business impact through strategic alignment, engineering excellence, and honest collaboration.
Are you ready to measure what success looks like in your organization?
In the field of performance engineering in FinTech, milliseconds are no longer just a measure of speed but rather the currency of success. Trust, revenue, and reputation are negatively affected by every delayed transaction, slow query, or missed execution, leading to a compounding effect that most businesses cannot bear.
For financial products aimed at real-time execution, performance is not a secondary concern; it is the very basis. It determines the quality of the users’ experience on your platform, how investors view the reliability of your company, and ultimately, how your organization competes in the market where precision and speed are inseparable.
Through working alongside large-scale custom software development in the FinTech segment, we’ve experienced that performance isn’t just about building efficient code or simply scaling your servers. Performance is about the system remaining constant during unpredictable events, such as trading peaks, surges in payments, or general market volatility. The real craft of performance engineering on FinTech is undeniably based on creating reliability at the speed of money.
Below are the five key success factors that will describe how the top-performing FinTech companies engineer speed, accuracy, and trust, not as desirable market buzz words, but tangible and measurable results.
1. Understanding Real-Time Performance Requirements: Where Milliseconds Matter Most
In a high-frequency trading system and real-time payments processing, even a minor delay can lead to a million-dollar loss. The concept of “real-time” differs among the sectors. For a financial market, it might imply microsecond execution; for a payment processing network, it would indicate a total transaction time of less than 200 milliseconds from the start to the clearing.
That’s the rationale for having explicit service-level objectives as an absolute requirement. Prior to constructing, teams must agree on the definition of performance against their business case, transaction throughput, latency, or resilience under load. The clarity of a given threshold drives every downstream decision: architecture, infrastructure, or deployment strategy, even.
A case in point is Hyperface, a credit-card platform that has achieved sub-200-millisecond transaction times across millions of daily operations by adopting a latency-first approach on AWS. Understanding performance requirements is the first layer of FinTech application optimization, because you can’t improve what you haven’t defined.
2. Architecture Patterns for High Performance: Designing Systems That Never Blink
A FinTech platform is only as strong as the architecture beneath it. Building for real-time responsiveness demands that teams think they go above simple scalability and focus on latency and observability from day one.
Modern software performance engineering in FinTech relies on event-driven microservices; each of the components, such as payments, trading, risk analysis, and fraud detection, works independently, reducing any sort of dependency that causes bottlenecks. Caching strategies, message queues like Kafka or RabbitMQ, and load balancers play vital roles in keeping systems highly responsive, even when under extreme loads.
Network protocols also matter. Most of the high-performance systems have moved to gRPC or HTTP/3, which enables faster request handling and lowers overhead. Meanwhile, the regional data replication and edge caching ensure that customers experience the same reliability from anywhere around the world. When architecture is treated as a living system, continuously tuned for financial software performance, real-time readiness becomes a cultural habit, not a technical challenge.
3. Performance Testing for Finance: The Discipline of Continuous Validation
FinTech systems fail mainly because they were not designed to scale; rather, they have never been properly tested for it. Finance performance testing is not a random checklist; it is a continuous process. Market changes, user behavior changes, and the number of integrations increases; therefore, testing must follow the change in all these aspects.
Teams that do well in real-time financial applications integrate testing directly into their CI/CD pipelines. Each and every release is automatically validated for latency, concurrency, and fault tolerance before going live. Tools such as Apache JMeter and Gatling simulate authentic traffic patterns to unveil how systems behave under real-world stress, while the tools that are meant to observe, such as Grafana and Prometheus, turn that data into actionable insight.
Different test types reveal different aspects: load tests provide information on the maximum sustainable throughput, stress tests give the limits of the system, and spike tests determine the recovery time of systems after sudden surges. All these tests combined provide an always-on safety net that guarantees both uptime and good user experience.
4. Optimization Techniques That Matter: Balancing Speed, Scale, and Security
Optimization is where performance engineering becomes a craft. It is not merely about cutting milliseconds from a single API call; rather, it is about establishing a full ecosystem where every component works together harmoniously. Fintech application optimization, on the other hand, is a case of only a few tiny technical choices resulting in large business profits. At the application layer, besides reducing API calls, refactoring slow endpoints, and caching so that quick access is always available to all frequently used data, faster execution is the result of all these.
Then there is the database optimization aspect through indexing and partitioning, or simplification, all done to reduce latency. At the surface level of the infrastructure layer, teams enhance payment processing performance by adopting various workflows and fine-tuning TLS configurations without ever putting compliance at risk.
Looking at the Network-level optimization is equally critical; leveraging content delivery networks or edge computing helps sustain a consistent performance globally. The most advanced and highly equipped teams use AIOps platforms such as Dynatrace to proactively identify any anomalies, using predictive analysis to prevent any sort of degradation before users ever notice.
5. Monitoring and Continuous Improvement: Turning Data into Foresight
Even the best-optimized environment will only remain performant if it is being consistently monitored. Financial software will not provide long-term performance unless it has an appropriate monitoring strategy – one that can not only identify a software failure but also predict a failure.
Engineering performance in FinTech means instrumentation of your entire layer of software (infrastructure and resource metrics, through API metrics to transaction metrics). Real-time dashboards and alerting methods need to identify deviations immediately, enabling engineers a chance to remediate the defect before the performance impacts a customer.
Predictive analytics is continuing the monitoring evolution, enabling the ability to identify problems before they happen, based on measured patterns across transaction volumes, CPU usage, and network use. Tools with an Artificial Intelligence (AI) engine will be able to predict performance bottlenecks and potentially recommend remediation strategies. This level of SWOT analysis is made possible at a massive scale by platforms such as AWS CloudWatch and AppDynamics.
The Competitive Edge of Millisecond Thinking
At Telliant Systems, we view performance engineering for real-time FinTech applications as an ongoing commitment to excellence, rather than a one-time success. In an industry where milliseconds determine the market leader, we support our clients in building systems that are engineered and perform reliably, today, tomorrow, and under any market condition.
Last year, a product manager I know tried running a complex simulation on their cloud platform. The job failed again and cost them over 200 compute hours. They weren’t even close to the answer. He joked that if he had a machine from the future, it might have finished in time for the next board meeting. He wasn’t far off.
That conversation made me stop and rethink what’s ahead. We’re building faster servers, better software, and sharper models, but some problems still take too long. That’s where quantum computing steps in.
It’s not a replacement for what we have. Not yet. But it’s close enough now that your software team should be paying attention.
Let’s take a closer look at where quantum computing stands today, the tools you can use, how businesses are starting to apply it, what hurdles remain and what your team can do right now to get ahead.
State of Quantum Today: What It Is and Where It Stands
Traditional computers use bits, which are either 0 or 1. Quantum computers use qubits, which can be 0, 1, or both at once. That’s because of something called superposition. And when qubits affect each other, no matter how far apart, that’s called entanglement.
Put simply, quantum computers aren’t just faster; they think differently. That makes them powerful for solving problems that would take classical computers forever to work through, like modelling molecules or optimising huge systems.
But we’re not fully there yet. Right now, we’re in what’s called the NISQ era, Noisy Intermediate-Scale Quantum. Quantum computers exist, but they’re still fragile, error-prone, and only able to run small-scale experiments. Qubits lose their quantum state quickly (this is called decoherence), and they’re extremely sensitive to interference.
That said, progress is moving fast. Companies like IBM, Google, AWS, and Microsoft are investing billions into quantum research and cloud-based access.
For example:
-
IBM Quantum
Offers real quantum computers online for developers to try.
-
AWS Braket
Gives access to different quantum hardware vendors via one interface.
-
Azure Quantum
Lets you experiment with quantum algorithms directly in Microsoft’s ecosystem.
You don’t need to own hardware to try it. Services like IBM Quantum, AWS Braket, and Azure Quantum offer developer access to quantum processors through the cloud.
But how do you actually build quantum software? That’s where the right tools come in.
Technical Frameworks That Let You Build for Quantum
Quantum programming doesn’t have to start from scratch. Today’s SDKs and libraries give you a clear way to prototype, test, and simulate code, even if you’ve never worked on a quantum machine.
Here are the main platforms helping developers bridge theory and practice:
-
Qiskit (by IBM)
An open-source SDK based on Python. It is great for learning, simulating, and even running code on real IBM quantum machines.
-
Braket (by AWS)
A service that gives you access to different quantum backends (including IonQ and Rigetti) with one interface. You can build hybrid quantum/classical workflows and access managed notebooks.
-
Azure Quantum SDK:
Part of Microsoft’s ecosystem. It lets you build quantum apps using Q#, while managing classical-quantum operations through standard IDEs like Visual Studio Code.
-
Cirq (by Google)
A Python library tailored for near-term quantum algorithms. It focuses on fine-grained control and experimentation in the NISQ environment.
All these tools come with simulators to prototype workflows, meaning you can test logic and performance without needing a real quantum processor.
If you’re wondering whether these frameworks are useful now, the answer is yes. They’re already the backbone of most modern Qiskit development and early-stage enterprise quantum readiness programs.
And as these SDKs evolve, companies are already exploring where quantum delivers real value. But how can you actually use this in a real business?
How Enterprises Are Using Quantum Today
Quantum computing may still be early, but it’s not just stuck in research labs. Enterprises are already exploring areas where they can make a measurable difference.
Some of the first real applications include:
-
Optimization problems
Things like delivery routes, factory scheduling, portfolio rebalancing, and supply chain modelling.
-
Monte Carlo simulations
Proprietary frameworks, pre-built components, and a mature DevOps pipeline reduce delivery times when compared to industry averages. Clients benefit from faster ROI without compromising quality.
-
Drug discovery and materials science
Simulating atomic-level interactions more efficiently than classical computers ever could.
-
Machine learning
Applying quantum models to speed up certain types of pattern recognition.
At the U.S. Department of Energy’s National Energy Research Scientific Computing Centre (NERSC), more than 50% of current production workloads fall under areas like materials science, quantum chemistry, and high-energy physics, exactly the domains where quantum computing is expected to deliver major advantages.
These aren’t theoretical matches. They’re high-priority national computing tasks already being mapped to quantum pipelines as the technology becomes more stable. When a government lab flags that half its compute demand aligns with quantum-ready domains, that’s a strong indicator of what’s coming.
Let’s look at what this looks like in real life.
In a manufacturing setup, researchers applied quantum computing to a robotic assembly line task. They transformed the problem of balancing workstations across a production line into a model solvable by a hybrid quantum-classical algorithm. When tested using a D-Wave quantum computer, the solution helped reduce idle time and improved how tasks were distributed across the line.
Many of these companies are building hybrid architectures, mixing classical systems with quantum accelerators, to test real workloads. If your organization is building for scale, this is something to pay attention to.
And companies like Telliant Systems are helping forward-thinking software teams explore these quantum-powered opportunities inside existing development workflows.
The Challenges We Still Need to Solve
Quantum computing isn’t plug-and-play. It comes with some big hurdles, and these are the key challenges that developers and decision-makers should understand:
-
Error correction
Qubits are fragile. Even small noise can produce the wrong result. Fixing that is one of the hardest problems in quantum tech.
-
Short decoherence times
Quantum states collapse fast. If the system can’t complete a calculation before that happens, the result is lost.
-
Cost and scalability
Building stable machines is expensive and scaling them is non-trivial.
-
Talent shortage
Few developers understand quantum programming. The learning curve is steep.
-
Early-stage tools
SDKs are improving, but many libraries are still experimental, and there’s little standardisation across platforms.
But here’s the thing: you don’t need perfect hardware to start learning. Open-source SDKs like Qiskit, along with cloud-based tools like Braket and Azure Quantum, are helping close the gap.
And because the field is still young, there’s room to grow. Quantum isn’t replacing classical computing. But learning it now gives your team a major head start.
How Software Teams Can Prepare Now
You don’t need to be a physicist to get started. Here’s how teams can begin preparing for the quantum future right now:
-
Start with the basics
Learn quantum logic, circuits, and linear algebra. Sites like Qiskit.org have free, structured lessons.
-
Try simulators
Platforms like Qiskit, AWS Braket, and Azure Quantum SDK let you build and test circuits without hardware
-
Identify possible use cases
Look for optimization problems or simulation bottlenecks in your business that quantum could improve
-
Track vendor roadmaps
IBM, Microsoft, and AWS regularly publish updates on hardware progress and language improvements.
-
Encourage cross-training
Classical and quantum developers can learn from each other. Building those bridges now makes adoption easier later.
The future of software isn’t about replacing what you already do; it’s about expanding what’s possible.
If you’re building modern systems and planning for scale, Telliant systems can help you prepare for quantum-driven opportunities.
Don’t Wait for Perfect Conditions
Quantum computing in software development isn’t a distant dream. It’s already shaping how we think about hard problems, and how we solve them faster, better, and more creatively.
The tools are ready. The platforms are growing. And the teams that start learning today will be tomorrow’s leaders.
Quantum computing in software development isn’t about waiting for perfect machines; it’s about building the knowledge to use them when they arrive.

