


































Feb 13th, 2024
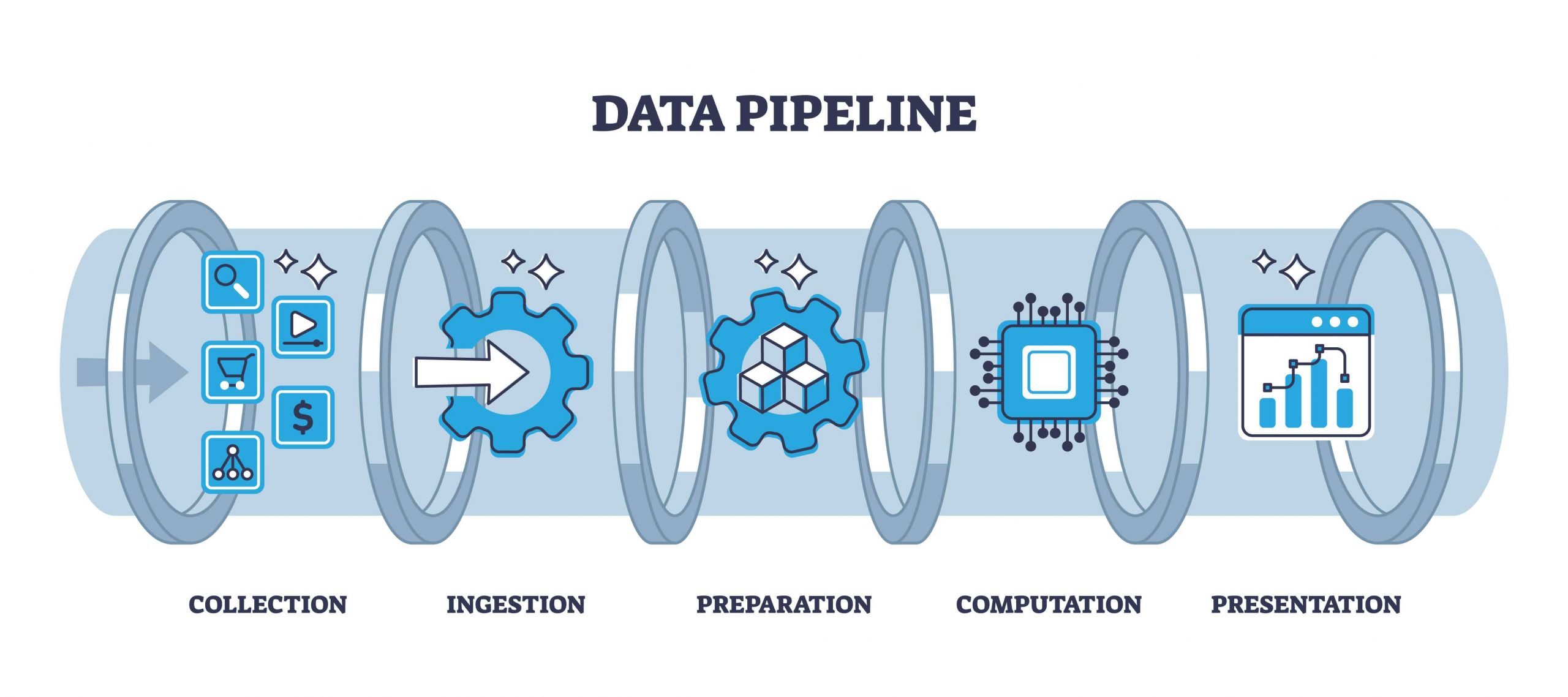
Key Techniques for Worry-Free Data Integration
Data integration is the process of merging data from disparate sources into one cogent dataset that can be used as a business’s source of truth. Combining data sources in this way allows a business to manage that data more efficiently, gain actionable insights from data, and create actionable plans for future projects.
What Types of business data benefit from integrations?
Any business with digital data stores, especially those with a lot of legacy storage solutions or many untracked storage solutions can benefit from data integration. There are 4 primary use cases for data integration:
- Data Ingestion: Moving data from a variety of sources to a single data lake, such as transferring data from local files to a cloud database.
- Data Replication: Copying and moving data from one source to another, such as creating a backup of data stored in a data lake.
- Data Warehouse Automation: Automating data storage lifecycle processes to make analysis of available data easier.
- Big Data Ingestion: Managing very large datasets so they can easily be piped into big data analytics tools. Requires advanced techniques and tooling.
Why is data integration important for modern businesses?
Modern business is data-driven. If you aren’t analyzing the data you collect from users, web traffic, brick-and-mortar transactions, internal teams, etc. you are missing out on opportunities to better understand your business and make more intelligent business decisions.
Most modern companies have data pouring in every second of every day. This is why streamlined, and sustainable data analysis solutions must be implemented. Integrating data from multiple sources is the first step.
Types of data sources
Depending on the type of business you run, you may have one or more of these types of data sources.
-
 Relational Databases
Relational Databases
-
Cloud Databases
-
APIs
-
Object Storage
-
File Repositories



5 Key Techniques of worry-free data Integration
- Manual Data Integration: Engineers write code that transfers data based on predefined requirements.
- Application-Based Data Integration: Third-party applications are accessed to move and transform data based on established triggers.
- Common Data Storage: Data from multiple sources is piped into a single data lake or data warehouse.
- Data Virtualization: Data from multiple sources is piped in a virtual database or cloud storage system where it is made available for analysis – sometimes via pre-built visualization and analytics tools.
- Middleware Data Integration: Either third-party or in-house software is used to move, analyze, or transfer data.
The way data is integrated will depend on the type and structure of data that needs to be integrated. A pipeline needs to be set up that understands the shape of the data, its origin and destination, and usually, its intended use.
What to watch out for when integrating data
The specific techniques used for data integration depend on a number of factors, including the volume and type of data to be integrated, the sources and destinations, the time and resources available, and the performance requirements of the new system.
Often, your available time and resources are the limiting factor. You may not have enough engineers available to write the code needed for a manual data integration, but you may not be able to afford the third-party software needed for an applications-based data solution. You can always consider hiring a software product development company if time and resources are the only limiting factors.
In this case, a tradeoff must be made, and you’ll need to keep in mind your goals when determining the best solution for you. Is your primary goal to maximize efficiency in data management, or to make data more easily accessible for your employees? Do you simply need to create a more robust storage solution? Do you have primarily internal or external data sources?
Questions like these will help you determine the correct path forward for your business when it comes to your particular data integration solution.





